
When: November 7, 2023
Where: Erlangen Centre for Astroparticle Physics (ECAP)
GitHub repository: https://github.com/carstenbauer/juliahep-hpctutorial
Link: https://pc2.de/go/jupyterhub
Most participants have access to the Noctua 2 cluster through the PC2 JupyterHub.
In this case, a browser is all that's needed!
JupyterKernel-Julia/1.9.3-foss-2022a-CUDA-11.7.0 and click on the appearing "Load" button.1_axpy_cpu.ipynb and, in the top right corner, select the kernel "Julia (8 threads) 1.9.3"."A time X plus Y"
$$ \vec{y} = a \cdot \vec{x} + \vec{y} $$Depending on the data type / precision:
Float32)Float64)function axpy_serial!(y, a, x)
#
# TODO: Implement the serial AXPY kernel (naively).
#
for i in eachindex(x,y)
@inbounds y[i] = a * x[i] + y[i]
end
return nothing
end
axpy_serial! (generic function with 1 method)
The performance of most scientific codes is memory-bound these days!
CPU (AMD EPYC 7763)
Peak compute performance over peak memory bandwidth
$$ \dfrac{3.5 \ [\textrm{TFlop/s}]}{200 \ [\textrm{GB/s}]} \cdot 8 \ \textrm{B} = 140 $$140 flops per number read, i.e. 8 bytes for Float64
GPU (NVIDIA A100)
Peak compute performance over peak memory bandwidth (only using CUDA cores)
$$ \dfrac{19.5 \ [\textrm{TFlop/s}]}{1.5 \ [\textrm{TB/s}]} \cdot 4 \ \textrm{B} = 52 $$52 flops per number read, i.e. 4 bytes for Float32
"Trick" question: How many bytes would be transferred in a non-inplace variant, i.e. z[i] = a * x[i] + y[i]? (Hint: It's likely not what you think 😉)
Let's benchmark the performance of our AXPY kernel.
using BenchmarkTools
const N = 2^30
a = 3.141
x = rand(N)
y = rand(N)
@btime axpy_serial!($y, $a, $x) samples=5 evals=3;
684.802 ms (0 allocations: 0 bytes)
Is this fast? What should we compare it to?
Let's look at the memory bandwidth (data transfer to/from memory per unit time) and the compute performance (flops per unit time) instead.
using BenchmarkTools
function generate_input_data(; N, dtype, kwargs...)
a = dtype(3.141)
x = rand(dtype, N)
y = rand(dtype, N)
return a,x,y
end
function measure_perf(f::F; N=2^30, dtype=Float64, verbose=true, kwargs...) where {F}
# input data
a,x,y = generate_input_data(; N, dtype, kwargs...)
# time measurement
t = @belapsed $f($y, $a, $x) evals = 2 samples = 10
# compute memory bandwidth and flops
bytes = 3 * sizeof(dtype) * N # TODO: num bytes transferred in AXPY kernel (all iterations)
flops = 2 * N # TODO: num flops performed in AXPY kernel (all iterations)
mem_rate = bytes * 1e-9 / t # TODO: memory bandwidth in GB/s
flop_rate = flops * 1e-9 / t # TODO: flops in GFLOP/s
if verbose
println("Dtype: $dtype")
println("\tMemory Bandwidth (GB/s): ", round(mem_rate; digits=2))
println("\tCompute (GFLOP/s): ", round(flop_rate; digits=2))
end
return mem_rate, flop_rate
end
measure_perf (generic function with 1 method)
measure_perf(axpy_serial!);
Dtype: Float64 Memory Bandwidth (GB/s): 37.13 Compute (GFLOP/s): 3.09
This is about 20% of the theoretical value for one entire CPU (with 64 cores). This will serve as our single-core performance reference point.
SIMD: axpy_serial! is already parallel at instruction level
@code_native debuginfo=:none axpy_serial!(y,a,x)
.text .file "axpy_serial!" .globl "julia_axpy_serial!_1072" # -- Begin function julia_axpy_serial!_1072 .p2align 4, 0x90 .type "julia_axpy_serial!_1072",@function "julia_axpy_serial!_1072": # @"julia_axpy_serial!_1072" .cfi_startproc # %bb.0: # %top pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset %rbp, -16 movq %rsp, %rbp .cfi_def_cfa_register %rbp pushq %r15 pushq %r14 pushq %r13 pushq %r12 pushq %rbx andq $-32, %rsp subq $96, %rsp .cfi_offset %rbx, -56 .cfi_offset %r12, -48 .cfi_offset %r13, -40 .cfi_offset %r14, -32 .cfi_offset %r15, -24 vxorpd %xmm1, %xmm1, %xmm1 vmovapd %ymm1, (%rsp) #APP movq %fs:0, %rax #NO_APP movq %rsp, %rcx movq -8(%rax), %r15 movq $8, (%rsp) movq (%r15), %rax movq %rax, 8(%rsp) movq %rcx, (%r15) movq 8(%rsi), %rbx movq 8(%rdi), %r12 cmpq %r12, %rbx jne .LBB0_11 # %bb.1: # %L22 testq %rbx, %rbx je .LBB0_10 # %bb.2: # %L31.preheader movq (%rsi), %rax movq (%rdi), %rcx movl $1, %edx cmpq $16, %rbx jb .LBB0_8 # %bb.3: # %vector.memcheck leaq (%rax,%rbx,8), %rsi cmpq %rsi, %rcx jae .LBB0_5 # %bb.4: # %vector.memcheck leaq (%rcx,%rbx,8), %rsi cmpq %rsi, %rax jb .LBB0_8 .LBB0_5: # %vector.ph movq %rbx, %rsi andq $-16, %rsi vbroadcastsd %xmm0, %ymm1 xorl %edi, %edi leaq 1(%rsi), %rdx .p2align 4, 0x90 .LBB0_6: # %vector.body # =>This Inner Loop Header: Depth=1 vmulpd (%rax,%rdi,8), %ymm1, %ymm2 vmulpd 32(%rax,%rdi,8), %ymm1, %ymm3 vmulpd 64(%rax,%rdi,8), %ymm1, %ymm4 vmulpd 96(%rax,%rdi,8), %ymm1, %ymm5 vaddpd (%rcx,%rdi,8), %ymm2, %ymm2 vaddpd 32(%rcx,%rdi,8), %ymm3, %ymm3 vaddpd 64(%rcx,%rdi,8), %ymm4, %ymm4 vaddpd 96(%rcx,%rdi,8), %ymm5, %ymm5 vmovupd %ymm2, (%rcx,%rdi,8) vmovupd %ymm3, 32(%rcx,%rdi,8) vmovupd %ymm4, 64(%rcx,%rdi,8) vmovupd %ymm5, 96(%rcx,%rdi,8) addq $16, %rdi cmpq %rdi, %rsi jne .LBB0_6 # %bb.7: # %middle.block cmpq %rsi, %rbx je .LBB0_10 .LBB0_8: # %scalar.ph decq %rdx .p2align 4, 0x90 .LBB0_9: # %L31 # =>This Inner Loop Header: Depth=1 vmulsd (%rax,%rdx,8), %xmm0, %xmm1 vaddsd (%rcx,%rdx,8), %xmm1, %xmm1 vmovsd %xmm1, (%rcx,%rdx,8) incq %rdx cmpq %rdx, %rbx jne .LBB0_9 .LBB0_10: # %L49 movq 8(%rsp), %rax movq %rax, (%r15) leaq -40(%rbp), %rsp popq %rbx popq %r12 popq %r13 popq %r14 popq %r15 popq %rbp .cfi_def_cfa %rsp, 8 vzeroupper retq .LBB0_11: # %L11 .cfi_def_cfa %rbp, 16 movq 16(%r15), %rdi movabsq $ijl_gc_pool_alloc, %r14 movl $1392, %esi # imm = 0x570 movl $16, %edx vzeroupper callq *%r14 movabsq $22590009144080, %r13 # imm = 0x148BA5787310 movl $1392, %esi # imm = 0x570 movl $16, %edx movq %r14, %rcx movq %rax, %r14 movq %r13, -8(%rax) movq %rbx, (%rax) movq %rax, 24(%rsp) movq 16(%r15), %rdi callq *%rcx movabsq $22590007128960, %rcx # imm = 0x148BA559B380 movq %r13, -8(%rax) movq %r12, (%rax) movq %rax, 16(%rsp) movabsq $22590030920368, %rdi # imm = 0x148BA6C4BAB0 leaq 48(%rsp), %rsi movl $3, %edx movq %rcx, 48(%rsp) movq %r14, 56(%rsp) movq %rax, 64(%rsp) movabsq $ijl_invoke, %rax movabsq $22590135223248, %rcx # imm = 0x148BACFC43D0 callq *%rax ud2 .Lfunc_end0: .size "julia_axpy_serial!_1072", .Lfunc_end0-"julia_axpy_serial!_1072" .cfi_endproc # -- End function .section ".note.GNU-stack","",@progbits
We want to parallelize our AXPY kernel via multithreading.
Julia provides the @threads macro to multithread for-loops.
Make sure that you actually have multiple threads in this Julia session! (I recommend 8 threads on Noctua 2.)
using Base.Threads: @threads, nthreads
@assert nthreads() > 1
nthreads()
8
function axpy_multithreading_dynamic!(y, a, x)
#
# TODO: Implement a naive multithreaded AXPY kernel (with @threads).
#
@threads for i in eachindex(y,x)
@inbounds y[i] = a * x[i] + y[i]
end
return nothing
end
axpy_multithreading_dynamic! (generic function with 1 method)
measure_perf(axpy_multithreading_dynamic!);
Dtype: Float64 Memory Bandwidth (GB/s): 39.04 Compute (GFLOP/s): 3.25
🙁 What's going on?! Why no (or not much) speedup?! 😢
Why pin threads?
How pin Julia threads? → ThreadPinning.jl
What about external tools like numactl, taskset, etc.? Doesn't work reliably because they often can't distinguish between Julia threads and other internal threads.
(More? See my short talk at JuliaCon2023 @ MIT: https://youtu.be/6Whc9XtlCC0)
using ThreadPinning
threadinfo()
System: 128 cores (no SMT), 2 sockets, 8 NUMA domains | 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15, 16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31, 32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47, 48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63 | | 64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79, 80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95, 96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111, 112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127 | # = Julia thread, | = Socket seperator Julia threads: 8 ├ Occupied CPU-threads: 8 └ Mapping (Thread => CPUID): 1 => 72, 2 => 112, 3 => 111, 4 => 123, 5 => 85, ...
pinthreads(:cores)
threadinfo()
System: 128 cores (no SMT), 2 sockets, 8 NUMA domains | 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15, 16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31, 32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47, 48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63 | | 64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79, 80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95, 96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111, 112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127 | # = Julia thread, | = Socket seperator Julia threads: 8 ├ Occupied CPU-threads: 8 └ Mapping (Thread => CPUID): 1 => 0, 2 => 1, 3 => 2, 4 => 3, 5 => 4, ...
pinthreads(:sockets)
threadinfo()
System: 128 cores (no SMT), 2 sockets, 8 NUMA domains | 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15, 16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31, 32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47, 48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63 | | 64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79, 80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95, 96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111, 112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127 | # = Julia thread, | = Socket seperator Julia threads: 8 ├ Occupied CPU-threads: 8 └ Mapping (Thread => CPUID): 1 => 0, 2 => 64, 3 => 1, 4 => 65, 5 => 2, ...
pinthreads(:cores)
measure_perf(axpy_multithreading_dynamic!);
Dtype: Float64 Memory Bandwidth (GB/s): 38.11 Compute (GFLOP/s): 3.18
Still the same performance?! 😢
NUMA = non-uniform memory access
One (of two) AMD Milan CPUs in Noctua 2:

Image source: AMD, High Performance Computing (HPC) Tuning Guide for AMD EPYCTM 7003 Series Processors

threadinfo(; groupby=:numa) # switch from socket/CPU grouping to NUMA grouping
System: 128 cores (no SMT), 2 sockets, 8 NUMA domains | 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 | | 16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31 | | 32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47 | | 48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63 | | 64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79 | | 80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95 | | 96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111 | | 112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127 | # = Julia thread, | = NUMA seperator Julia threads: 8 ├ Occupied CPU-threads: 8 └ Mapping (Thread => CPUID): 1 => 0, 2 => 1, 3 => 2, 4 => 3, 5 => 4, ...
using NUMA, Random
data = Vector{Float64}(numanode(1), 100); rand!(data);
which_numa_node(data)
1
data = Vector{Float64}(numanode(8), 100); rand!(data);
which_numa_node(data)
8
Let's do a quick and dirty benchmark to get an idea how much this matters for performance.
node1 = current_numa_node()
node2 = mod1(current_numa_node() + nnumanodes()÷2, nnumanodes()) # numa node in other CPU/socket
println("local NUMA node")
x = Vector{Float64}(numanode(node1), N); rand!(x)
y = Vector{Float64}(numanode(node1), N); rand!(y)
@btime axpy_serial!($y, $a, $x) samples=5 evals=3;
println("distant NUMA node")
x = Vector{Float64}(numanode(node2), N); rand!(x)
y = Vector{Float64}(numanode(node2), N); rand!(y)
@btime axpy_serial!($y, $a, $x) samples=5 evals=3;
local NUMA node 727.537 ms (0 allocations: 0 bytes) distant NUMA node 1.052 s (0 allocations: 0 bytes)
Note that the performance issue will be mouch more pronounced in multithreaded cases, where different threads might try to access the same non-local data over the same memory channel(s).
→ "First-touch" policy
x = Vector{Float64}(undef, 10) # allocation, no "touch" yet
rand!(x) # first touch == first write
pinthreads(:numa)
threadinfo(; groupby=:numa)
System: 128 cores (no SMT), 2 sockets, 8 NUMA domains | 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 | | 16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31 | | 32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47 | | 48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63 | | 64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79 | | 80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95 | | 96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111 | | 112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127 | # = Julia thread, | = NUMA seperator Julia threads: 8 ├ Occupied CPU-threads: 8 └ Mapping (Thread => CPUID): 1 => 0, 2 => 16, 3 => 32, 4 => 48, 5 => 64, ...
for tid in 1:8
@sync @tspawnat tid begin # ThreadPinning.@tspawnat creates *sticky* tasks that don't migrate between threads
x = Vector{Float64}(undef, 10) # allocation, no "touch" yet
rand!(x) # first touch
@show tid, which_numa_node(x)
end
end
(tid, which_numa_node(x)) = (1, 1) (tid, which_numa_node(x)) = (2, 2) (tid, which_numa_node(x)) = (3, 3) (tid, which_numa_node(x)) = (4, 4) (tid, which_numa_node(x)) = (5, 5) (tid, which_numa_node(x)) = (6, 6) (tid, which_numa_node(x)) = (7, 7) (tid, which_numa_node(x)) = (8, 8)
Question
using Random
function generate_input_data(; N, dtype, parallel=false, kwargs...)
a = dtype(3.141)
x = Vector{dtype}(undef, N)
y = Vector{dtype}(undef, N)
if !parallel
rand!(x)
rand!(y)
else
#
# TODO: initialize x and y in parallel
# (in the same way as we'll use it in the axpy kernel)
#
@threads for i in eachindex(x,y)
x[i] = rand(dtype)
y[i] = rand(dtype)
end
end
return a,x,y
end
generate_input_data (generic function with 1 method)
pinthreads(:numa)
measure_perf(axpy_multithreading_dynamic!; parallel=false);
measure_perf(axpy_multithreading_dynamic!; parallel=true);
Dtype: Float64 Memory Bandwidth (GB/s): 38.86 Compute (GFLOP/s): 3.24 Dtype: Float64 Memory Bandwidth (GB/s): 164.81 Compute (GFLOP/s): 13.73
Speedup! Yeah! 😄 🎉
But.... less than expected!? 😕
Question
threadinfo(; groupby=:numa)
System: 128 cores (no SMT), 2 sockets, 8 NUMA domains | 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 | | 16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31 | | 32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47 | | 48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63 | | 64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79 | | 80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95 | | 96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111 | | 112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127 | # = Julia thread, | = NUMA seperator Julia threads: 8 ├ Occupied CPU-threads: 8 └ Mapping (Thread => CPUID): 1 => 0, 2 => 16, 3 => 32, 4 => 48, 5 => 64, ...
Conceptually, Julia implements task-based multithreading.
A user shouldn't care about threads but tasks!
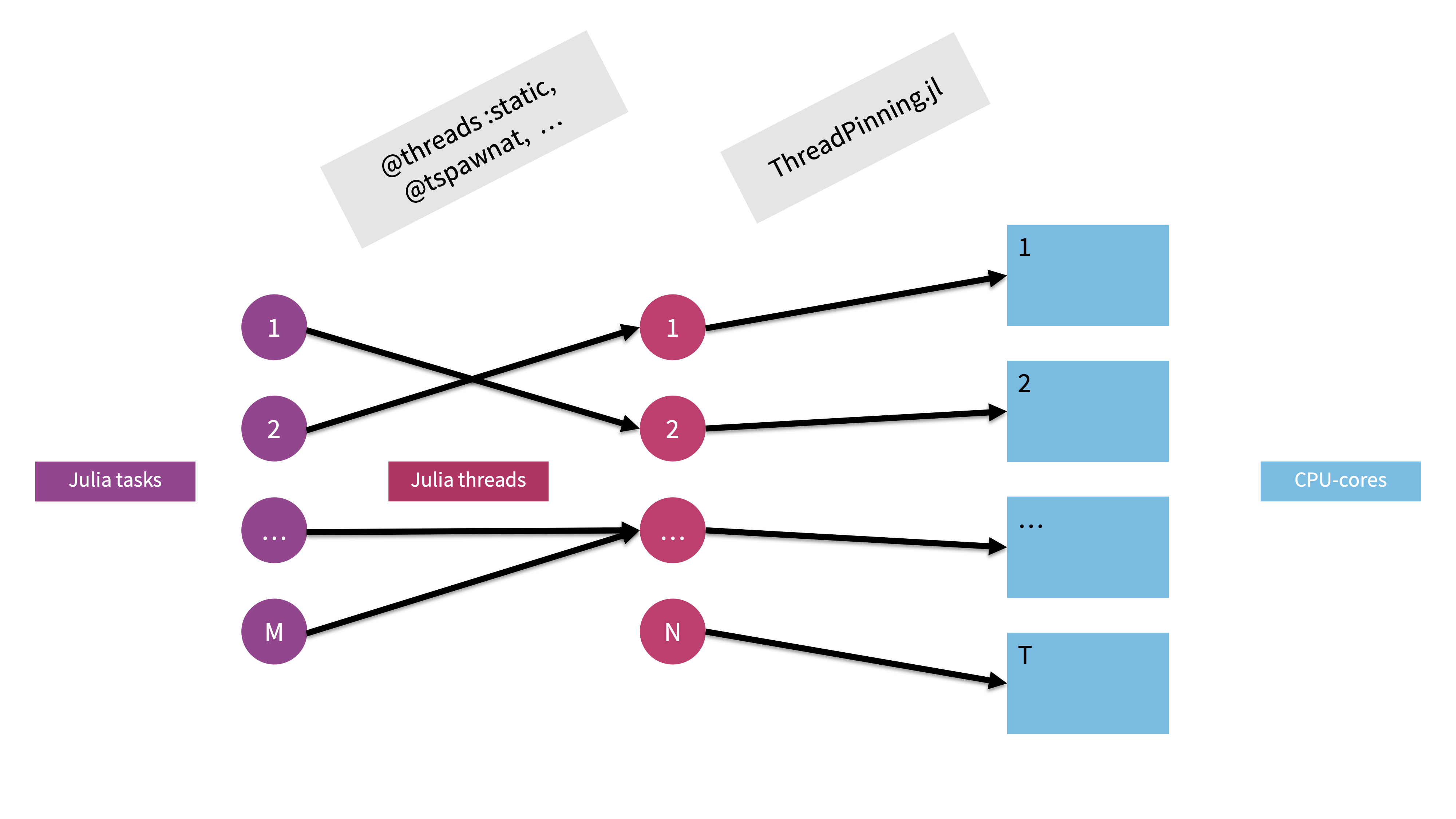
In "traditional" HPC, we typically care about threads directly, i.e. we tell every thread what it should do.
In Julia's task-based multithreading, a task - e.g. a computational piece of a code - is only marked for parallel execution (@spawn, @threads) on any of the available Julia threads. Julias dynamic scheduler will then take care of running the task on any of the threads (the task might even migrate!).
Advantages:
Disadvantages:
task → thread → core mapping.We can pt-out of Julia's dynamic scheduling and get guarantees about the task-thread assignment (and the iterations → task mapping).
Syntax: @threads :static for ...
nthreads() even, contiguous blocks (in-order) and creates precisely one task per blockIn short:
Dynamic scheduling: @spawn, @threads :dynamic (default)
Static scheduling (i.e. fixed task → thread mapping): ThreadPinning.@tspawnat, @threads :static
function axpy_multithreading_static!(y, a, x)
#
# TODO: Implement a statically scheduled multithreaded AXPY kernel (with @threads :static).
#
@threads :static for i in eachindex(x,y)
@inbounds y[i] = a * x[i] + y[i]
end
return nothing
end
axpy_multithreading_static! (generic function with 1 method)
We also need to adapt the input data generation.
function generate_input_data(; N, dtype, parallel=false, static=false, kwargs...)
a = dtype(3.141)
x = Vector{dtype}(undef, N)
y = Vector{dtype}(undef, N)
if !parallel
rand!(x)
rand!(y)
else
if !static
@threads for i in eachindex(x,y)
x[i] = rand(dtype)
y[i] = rand(dtype)
end
else
@threads :static for i in eachindex(x,y)
x[i] = rand(dtype)
y[i] = rand(dtype)
end
end
end
return a,x,y
end
generate_input_data (generic function with 1 method)
pinthreads(:numa)
measure_perf(axpy_multithreading_static!; parallel=false, static=true);
measure_perf(axpy_multithreading_static!; parallel=true, static=true);
Dtype: Float64 Memory Bandwidth (GB/s): 39.01 Compute (GFLOP/s): 3.25 Dtype: Float64 Memory Bandwidth (GB/s): 304.61 Compute (GFLOP/s): 25.38
Finally, we're in the ballpark of the expected speedup! 😄 🎉