The heat equation¶
We consider the heat equation, a partial differential equation (PDE) describing the diffusion of heat over time. The PDE reads
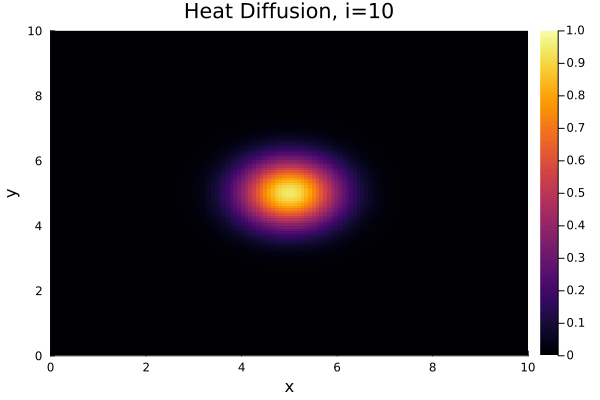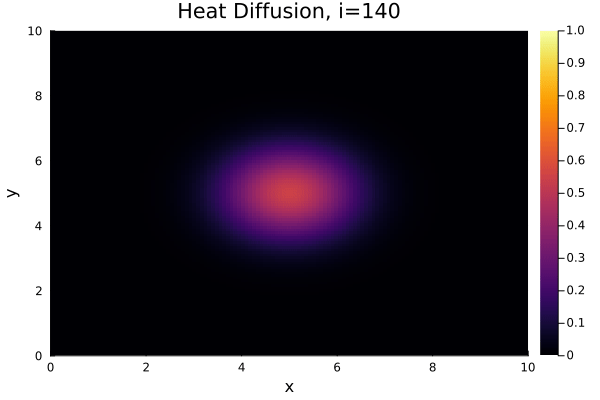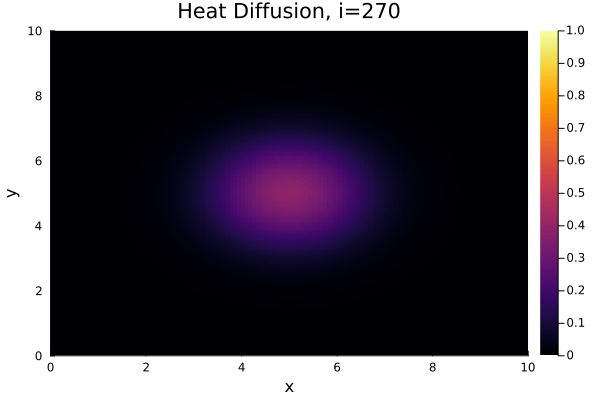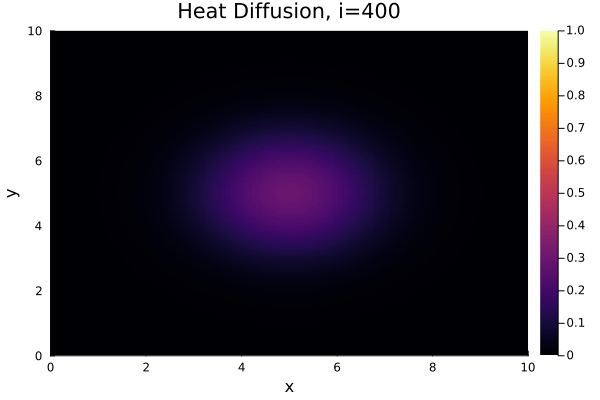
$$ \dfrac{\partial T}{\partial t} = \alpha \left( \dfrac{\partial^2 T}{\partial x^2} + \dfrac{\partial^2 T}{\partial y^2} \right), $$where the temperature $T = T(x,y,t)$ is a function of space ($x,y$) and time ($t$) and $\alpha$ is a scaling coefficient. Specifically, we'll consider a simple two-dimensional square geometry. As the initial condition - the starting distribution of temperature across the geometry - we choose a "Gaussian" positioned in the center.
Numerical solver¶
- We discretize space (
dx,dy) and time (dt) and evaluate everything on a grid. - We use the basic finite difference method to compute derivatives on the grid, e.g.
- We use a two-step process: a) Compute the first-order spatial derivates. b) Then, update the temperature field (time integration).
Note that the derivatives give our numerical solver the character of a stencil. Stencils are typically memory bound, that is, data transfer is dominating over FLOPs and consequently performance is limited by the rate at which memory is transferred between memory and the arithmetic units. For this reason we will measure the performance in terms of an effective memory bandwidth.
Result¶